1. 같은 프로세스 내의 여러 개의 쓰레드가 같은 메모리를 공유하는 것과 같이
오라클 DBMS 내부에서도 공유 메모리 영역이 존재한다.
2. 다음 그림과 같이 특정 기능과 목적에 따라 영역이 구분된다.
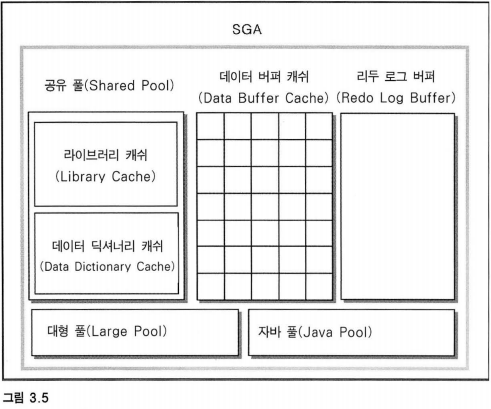
3. 각 영역에서 하는 기능이 무엇인지 차례대로 정리해보았다.
순서 : 공유 풀 -> 대형 풀 -> 데이터 버퍼 캐쉬 -> 리두 로그 버퍼 -> 자바 풀
연관 : 백그라운드 프로세스(DBWR), 래치와 락, NL 조인과 HJ 조인
4. 먼저 공유풀은 고정 영역과 동적 영역으로 다시 나뉘게 된다.
이렇게 보면 그림 3-5에 라이브러리 캐쉬, 데이터 딕셔너리 캐쉬는 왜 아래로 빼놓았는지 모르겠다.
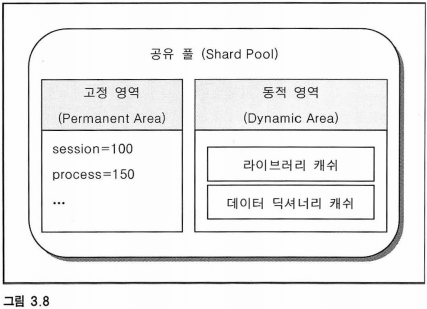
4.1 고정 영역
해당 영역에는 오라클이 SGA를 관리하는 메커니즘 및 오라클 파라미터 정보가 저장된다.
파라미터 정보는 SELECT * FROM V$SPPARAMETER 명령어로 확인할 수 있다.
아래 URL에 접속하면 파라미터의 종류를 확인할 수 있다.
상황과 환경에 맞게 파라미터 설정값을 다르게 하여 SGA 관리 메커니즘을 다양하게 설정할 수 있다.
http://dbcafe.co.kr/wiki/index.php/%EC%98%A4%EB%9D%BC%ED%81%B4_%ED%8C%8C%EB%9D%BC%EB%AF%B8%ED%84%B0
오라클 파라미터 - DB CAFE
1 파라미터 파일의 개념과 종류 1.1 파라미터 파일의 개념 오라클에서 말하는 필수 파일 중에서 파라미터 파일은 오라클이 구동 할 수 있게 설계되어 있는 도면과 같습니다. 한가지 예로 데이터
dbcafe.co.kr
4.2 동적 영역
해당 영역은 라이브러리 캐쉬와 데이터 딕셔너리 캐쉬로 구분된다.
11g 이상부터는 Server Result Cache 영역이 추가됐다.
4.2.1 라이브러리 캐쉬에 저장되는 항목
- 데이터베이스에 접속한 유저가 실행한 SQL
- 오라클이 내부적으로 사용하는 SQL(Recursive SQL)
- SQL에 대한 분석 정보(Parse Tree)
- 실행 계획(Execution Plan)
4.2.2 데이터 딕셔너리 캐쉬
테이블, 인덱스, 함수 및 트리거 등 오라클 오브젝트 정보 및 권한 등의 정보가 저장
4.3 공유 풀의 활용
SQL 관련된 정보는 라이브러리 캐쉬에 고유 오브젝트 관련된 정보는 딕셔너리 캐쉬에 저장되어 있는 것을
확인해볼 수 있는데 그렇다면 공유 풀은 언제, 어떻게, 무엇을 위해 활용되는 것인가
DBMS 내부의 서버프로세스가 SQL Query 문을 처리하는 과정을 자세히 살펴보면
Parse -> Execute -> Fetch 단계를 거쳐 최종 출력하는 모습을 볼 수 있다.
바로 이 Parse 단계에서 공유 풀이 활용되는 것이다.
4.4 SQL - Parse
쿼리문이 문법적으로 이상이 없는지, 테이블과 칼럼이 실존하는지, 접근 권한을 충족하는지 유효성 검증을 한 다음
옵티마이저를 통해 실행 계획을 수립한다.
위 단계까지 끝낸 SQL 문은 실행 계획, 컴파일된 코드(P-Code)와 함께 공유 풀의 Library cache의 SQL Area에 저장된다.
이에 따라 공유 풀에 저장된 쿼리문이 재실행되는 경우 Parse 단계를 생략하고 다음 단계로 진행할 수 있다. (Soft Parse)
공유 풀에 저장되지 않은 경우엔 Parse 단계를 거친다. (Hard Parse)
4.5 라이브러리 캐쉬 한계
라이브러리 캐쉬는 기본적으로 LRU 알고리즘을 사용하여 쿼리문을 저장 및 반환한다.
하지만 실행된 SQL문을 공유 풀에 무한정으로 저장할 수는 없다.
LRU 리스트 탐색에 실패하고 공유 풀에도 용량이 부족한 경우 ORA-4031 에러를 출력하는데
이를 방지하기 위해 예약 풀 또는 대형 풀을 사용할 수 있다.
4.5.1 예약 풀로 해결하기
공유 풀에서의 메모리 부족으로 인한 SQL 수행 실패를 방지하기 위한 별도의 메모리 공간이다.
SHARED_POOL_RESERVED_SIZE 파라미터로 메모리 크기를 설정할 수 있다.
임계치 이상으로 설정된 SQL문이 수행될 때 공유 풀과 예약 풀의 메모리를 함께 사용해서
메모리 부족으로 인한 실패를 방지할 수 있다.
4.5.2 대형 풀로 해결하기
공유 풀의 부하를 감소하기 위해 사용되는 것을 목적으로 한 선택적 메모리 공간이다.
공유 풀의 메모리 부족 현상을 해결한다는 점에서 예약 풀과 동일하지만 이외에도 여러 가지 기능이 제공된다.
5. 대형 풀
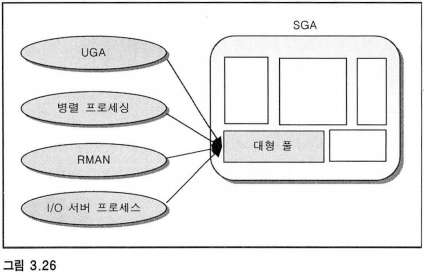
5.1 UGA(User Global Area)
세션 정보를 가지고 있는 메모리 공간으로 원래는 세션별로 할당된다.
하지만 공유 서버 환경에서 데이터베이스가 사용되는 경우 공유 풀에 메모리가 할당된다.
이 경우엔 공유 풀의 메모리 공간이 낭비(?)될 우려가 있기 때문에 대형 풀을 사용하여 메모리 낭비를 줄일 수 있다.
5.2 병렬 프로세싱
여러 개의 프로세스를 기동하여 하나의 SQL 문을 수행할 수 있게 하는 기능이다.
각 프로세스는 병렬 프로셋 메시지(PX MSG)를 이용해 데이터를 주고 받으면서 수행한다.
이에 따라 추가의 메모리 할당이 요구되고 문맥 교환에 따른 오버헤드가 발생할 수 있다.
이를 방지하기 위해 PARALLEL_AUTOMATIC_TUNING 값을 TRUE로 설정해 대형 풀에서 처리할 수 있도록 한다.
(JAVA의 ParallelStream과 비슷한 문제..)
5.3 RMAN(Recover MANager)
RMAN 유틸리티를 사용하면 여러 개의 디스크 I/O 슬레이브 프로세스를 사용할 수 있다.
이때 BACKUP_DISK_IO=n과 BACKUP_TAPE_IO_SLAVE_TRUE로 파라메터가 설정되어 있다면 대형 풀을 사용하게 된다.
만약 대형 풀 공간이 부족하다면 경고 메시지를 경고 로그 파일에 기록하고 백업 및 복구시 I/O 슬래이브(Slave) 프로세스를 사용하지 않게 된다.
5.4 I/O 서버 프로세스
DBWR 백그라운드 프로세서는 해당 프로세스 아래 슬래이브 프로세스(Slave Process)를 기동하여 더 빠른 디스크 I/O 작업을 수행할 수 있다.
I/O 슬래이브 프로세스들 사이에 통신을 수행하게 되며, 이때 대형 풀이 설정되어 있다면 대형 풀을 사용하게 된다.
슬레이브 프로세스를 사용하는 점에선 RMAN과 비슷해보인다.
RMAN과의 차이점은 RMAN 유틸리티를 사용하는지 DBWR 백그라운드 프로세스를 사용하는지에 있다.
그렇다면 DBWR 백그라운드 프로세스가 하는 역할은 무엇일까
~ 에 대해선 별도의 장에 기술하도록 하겠다.
6. 데이터 버퍼 캐쉬
하나의 SQL 쿼리문을 처리하기 위해 Parse, Execute, Fetch 세 단계를 수행한다는 것과
SQL 구문에 대해 Parse가 완료되면 공유 풀의 라이브러리 캐쉬에 저장하는 것까지는 확인했다.
그렇다면 실행 계획에 따라 데이터를 읽는 Execute 단계에서도 라이브러리 캐쉬와 비슷하게 동작하는
기능을 DBMS가 지원을 해줄까
정답은 데이터 버퍼 캐쉬에 있다.
6.1 디스크와 데이터 버퍼 캐쉬의 관계
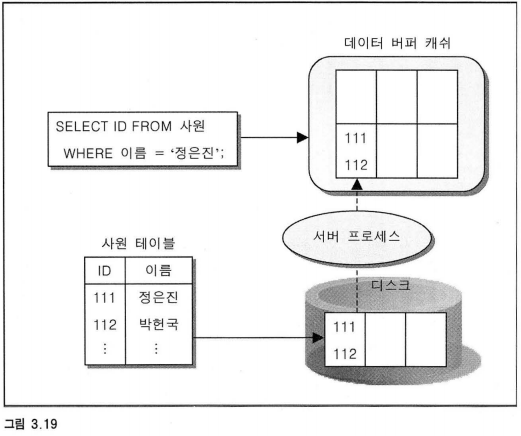
위 그림과 같이 디스크로부터 한 번 읽은 데이터는 서버 프로세스가 데이터 버퍼 캐쉬에 담아둔다.
이후 Execute 단계에서 캐쉬에 먼저 접근한 다음, 찾는 데이터가 없는 경우에만 디스크 I/O 연산을 수행한다.
라이브러리 캐쉬와 비슷한 메커니즘을 가지며 LRU 알고리즘을 사용하는 것 또한 동일하다.
6.2 DBWR 백그라운드 프로세서
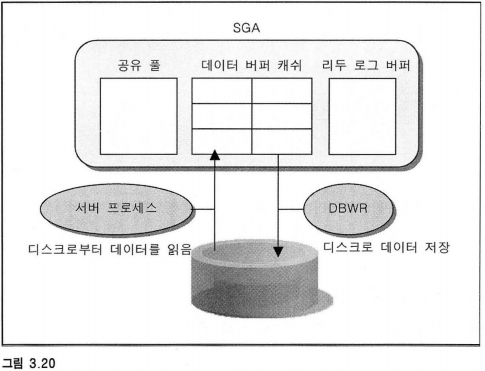
반대로 데이터 버퍼 캐쉬에서 데이터 블록의 변경이 일어난 경우 해당 내용은 DBWR가 디스크로 저장시킨다.
그 이유에 대해선 버퍼의 상태 4가지를 먼저 이해해야 한다.
6.2.1 버퍼의 상태와
기본적으로 버퍼의 상태는 4가지로 나뉜다.
- Free : 빈 공간
- Clean : 버퍼의 값과 디스크(파일)의 값이 일치한 경우
- Pinned : 다른 세션에서 해당 버퍼를 Lock 잡고 있는 경우
- Dirty : 버퍼의 값과 디스크(파일)의 값이 불일치한 경우
Free와 Clean 상태인 데이터를 참조하는 경우 캐쉬에 저장된 값을 참조해도 문제가 발생하지 않는다.
하지만 Pinned 상태인 경우에는 데이터에 접근할 수 없고
또한 Dirty 상태인 경우엔 잘못된 데이터를 참조할 우려가 있다.
바로 DBWR가 Dirty 상태로부터 발생하는 비일관성을 바로잡아 주는 역할을 하는 것이다.
6.2.2 DBWR의 역할
DBWR은 주기적으로 Dirty 상태를 갖는 버퍼를 Free 상태로 변경해줌과 동시에 Dirty List에 해당 데이터를 적재한다.
그 후 Dirty List에 있는 데이터를 다음과 같은 상황이 발생할 때 디스크(파일)로 옮겨준다.
- Dirty List의 값이 일정 임계값에 도달할 때
- 지정된 시간 주기마다
- LRU List에서 Free인 버퍼를 찾는 시간이 임계값 이상 넘어가는 경우, Dirty 상태인 버퍼를 디스크로 옮기면서 해당 갯수만큼 Free 버퍼를 만들어낸다.
- 메모리와 디스크를 동기화해주는 작업인 Checkpoint가 발생하는 경우
6.3. 고려해볼만한 사항 - 데이터 블록의 크기
오라클은 데이터를 블록 단위로 가져오기 때문에 데이터 블록이라는 단어를 반복했다.
원래는 8KB가 고정이었으나 9i 버전 이후 2,4,8,16KB로 조정할 수 있게 됐다.
공유 풀의 고정 영역에 있는 initSID.ora의 DB_BLOCK_SIZE 파라미터 값에서 설정 가능하다.
6.3.1 데이터 블록의 크기를 크게 경우
한 번의 디스크 I/O로 데이터를 많이 가져올 수 있기 때문에 캐시 적중률이 높다면 효율적이다.
재참조(SELECT)될 확률이 높기 때문이다.
그러나 다수의 유저가 가져온 데이터 블록에 대해 DML 연산을 수행하는 경우 많은 '경합'이 발생할 수 있다.
6.3.1 데이터 블록의 크기를 작게 설정한 경우
경합이 발생할 수 있는 확률을 줄일 수 있지만 많은 디스크 I/O를 발생시킬 수 있다는 단점이 있다.
조금만 생각해보면 알 수 있는 원리이고 운영 환경과 각 상황에 맞게 판단하면 될 것 같다.
그럼에도 불구하고 좀 더 완벽에 가까운 세밀한 설정이 가능할까?
6.4 다중 데이터 버퍼 캐쉬 설정
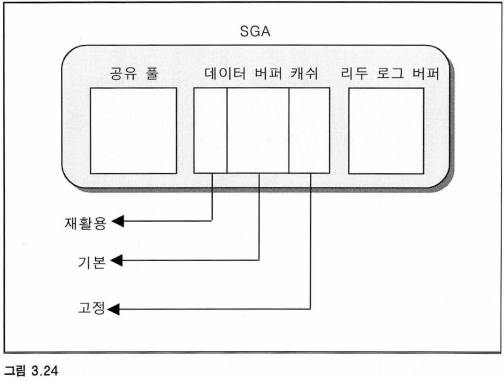
세 개의 영역으로 나눠서 관리가 가능한데 데이터 재사용율이 구분 기준이다.
각각의 영역은 독립적인 LRU 스케쥴링을 가진다. 파라미터 값을 수정해서 크기 조절을 할 수 있다.
데이터가 재사용될 확률이 높다고 판단할 경우 고정 영역에 배치를 시키고
그렇지 않은 경우는 재활용 영역에 저장시켜 빠르게 메모리에서 제거되도록 한다.
자주 사용되는 코드성 테이블이나 성능 좋은 테이블 인덱스는 고정 영역에 배치시키는 것이 올바르다.
7. 리두 로그 버퍼(Redo Log Buffer)
7.1 기능 및 목적
DBMS의 트랜잭션 원자성(ACID)을 보장하기 위해 도입된 기능이다.
해당 버퍼가 하는 기능은 변경된 사항을 로그로 남겨 임시 저장을 하는 것이다.
여기서 말하는 변경된 사항은 무엇일까?
DDL에 의한 오브젝트 변경, DML에 의한 데이터 변경을 의미한다.
7.2 동작 과정
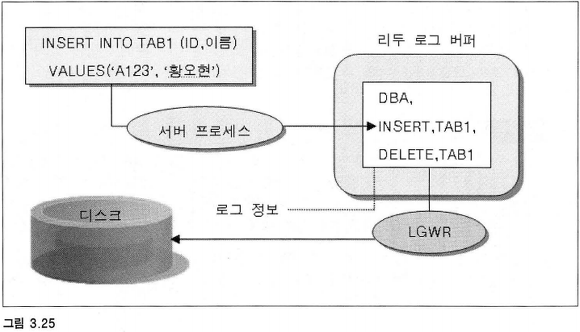
변경된 사항은 서버 프로세스에 의해 리두 로그 버퍼에 저장한 후
백그라운드 프로세스(LGWR)에 의해 리두 로그 파일에 저장한다.
7.3 로그를 저장하는 이유
변경된 사항이 정상적으로 반영이 되지 않은 경우 리두 로그 버퍼에 있는 데이터를 읽어서 재기록을 수행하거나( ROLLFOWARD)
원래 상태로 복구시켜야 하기 때문이다.(ROLLBACK)
8. 자바 풀
존재감도 가장 낮고 크기고 가장 적은 공유 메모리 영역
JAVA 구문을 해석하기 위해 사용되는 메모리 공간이다.
-끝-
'공부 이야기 > 데이터베이스' 카테고리의 다른 글
| "Can't connect to MySQL server on '127.0.0.1' ([WinError 10061] 대상 컴퓨터에서 연결을 거부했으므로 연결하지 못했습니다)") (0) | 2024.02.08 |
|---|---|
| [Oracle] PGA 사용자별 할당 메모리 영역 (0) | 2022.12.12 |
| NL 조인, Hash Join (0) | 2022.12.09 |
| [DATABASE] 인덱스 사용시 주의사항 (0) | 2021.10.07 |
| NESTED JOIN 처리 과정 (0) | 2020.09.12 |


