1. 범주형 데이터 vs 양적 데이터
- 수치적으로 계산을 할 수 있는지에 따라 구분
- 단, 양적 데이터에선 수학 연산이 된다고 무조건 결과가 의미 있지는 않음
2. 이항분포
- P와 1-P의 확률을 가질 때의 이산 확률 분포
ex) 동전 던지기
- 이처럼 두 가지 경우일 때를 베르누이 시행, n=1가 될 때는 베르누이 분포라고 함 (n은 시행 횟수)
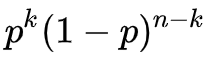
3. 베이즈 이론
- 단순히 모든 경우의 수에 대해 확률을 구하는 것이 아닌, 특정 조건을 사전에 걸 필요가 있을 경우 사용
- 추론 대상의 사전 확률과 추가적인 정보를 기반으로 해당 대상의 사후 확률을 추론하는 통계적 방법
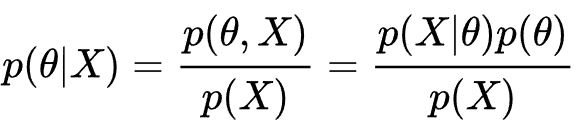
4. 부트스트랩
- 1부터 N개의 모수 중에서 하나씩 샘플로 뽑는 과정에서 하나씩 추가할 때마다 전체 평균을 계속 계산하는 방법
- N개의 표본이 아닌, N(N-1) / 2개의 확장된 표본 값을 얻을 수 있음 -> 모수의 신뢰구간을 높일 수 있음
5. 가설 검정
- 새로운 주장을 펼치거나 이론을 내세울 때 이를 검정하는 기법으로 귀무 / 대립으로 가설을 나눠서 검정한다.
- 귀무가설 (H0) : 과거에 있었던 데이터를 기반으로 하는 가설
- 대립가설 (H1) : 새롭게 제기된 가설
-> 즉, 하나의 이론에 대해 두 개의 가설을 A와 B로 두고 하나만을 채택한다는 개념이 아닌, 귀무가설을 따를지 대립가설을 따를지로 나누는 방식임
- 제 1종 과오 : 귀무가설이 참인데 이를 기각하는 경우 -> 허용한계 α = P(기각ㅣ참)
- 제 2종 과오 : 귀무가설이 거짓인데 이를 채택하는 경우 -> 허용한계 β = P(참ㅣ기각)
- P value : 귀무가설이 참이라는 전제 하에 측정치 대비 통계치를 계산하는 것. α보다 작을 경우 귀무가설을 기각된다.
6. 본페로니 교정
- P value를 산출하는 과정 중에서 n번 반복할 때마다 오류치가 산술적으로 늘어나는 것을 방지하기 위해
다시 α / n으로 나눠주어 값을 보정하는 것
'공부 이야기 > 그냥 찾아보는 공부' 카테고리의 다른 글
| Kotlin vs JAVA in 객체 초기화, 데이터 정의 (0) | 2020.11.01 |
|---|---|
| 안드로이드 운영체제 - HAL (0) | 2020.11.01 |
| Angular JS란? (0) | 2020.02.28 |
| Angular Framework는 무엇인가? (0) | 2020.02.27 |
| Github 사용법 배우기 (0) | 2020.01.23 |

